For a long, long time, I never used any kind of source code control. Which was counter-productive, because tracking changes was hard, and so was managing patches.
Nowadays I'm trying to familiarise myself with
Git, the SCM used for the Linux kernel and also k42. Jeff is working on a
Quilt-like addition to Git called
Guilt, which I learned how to use today. Guilt, like Quilt, works on a series of patches which are applied in the form of a stack. You can push and pop patches from the stack, as you build patches one on top of another.
Guilt needs to be used together with Git, although you can probably not bother with most of Git when you have Guilt in place.
See
here and
here for some quick tutorials to Git. You'll need to have it set up before you can use Guilt.
The first thing you need to do is to get the source (no Debian packages yet, sorry):
$ git-clone git://git.kernel.org/pub/scm/linux/kernel/git/jsipek/guilt.git
This will set up a repository in your current directory. You can use
make install PREFIX=/path/to/prefix to install it after which you should be able to use Guilt.
Now, suppose you have a git repository which you want to hack on. Say, the Linux kernel.
$ git-clone git://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux-2.6.git linux-2.6
Now you have a shiny source tree with a
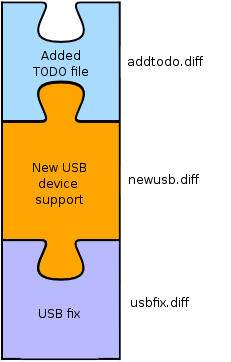
.git/ subdirectory. Now, suppose you want to release a series of patches containing, say, a USB fix, support for a new USB device, and add a TODO file.
First thing you do is initialise the git repository to work with guilt
$ guilt-init
This creates a
.git/patches/master/{series,status} subdirectory which is initially empty.
Then you decide to work on the USB patch. First you create the patch (in this example named
usbfix.diff):
$ guilt-new usbfix.diff
This will create a new patch, and push it onto your patch stack.
Now you can hack up some code for the USB fix, and then when you're done, you tell Guilt about your changes:
$ guilt-refresh
If you check in the
.git/patches/master subdirectory, you'll find a shiny new patch named
usbfix.diff. If you look at the output, it looks like a standard patch that you create using
diff. The patch is created automagically!
If you want to add another patch on top of that, you can run
guilt-new again:
$ guilt-new newusb.diff
Hack some more. Do a
guilt-refresh.
$ guilt-refresh
You get the picture.
Now let's say you notice your first fix in
usbfix.diff introduced a new bug (stuff like this happens all the time to me). So what you do is you pop the patch before
usbfix.diff:
$ guilt-pop
That temporarily pops out the
newusb.dif patch, allowing you to fix the code which concerns only the first patch. Once you're done fixing, run
guilt-refresh again to update
usbfix.diff:
$ guilt-refresh
After that, push the
newusb.diff patch back onto the stack:
$ guilt-push newusb.diff
After that you can either resume working on
newusb.diff, or start a new patch with
guilt-new.
Now let's say you wanted to introduce a new file called
TODO into the source tree, and have a patch for that.
$ guilt-new addtodo.diff
Then you create a new file called TODO and write stuff in it. After that, you add the file to Guilt:
$ guilt-add TODO
Finally, to update the patch run:
$ guilt-refresh
At the end of your hacking you'll end up with a stack of patches like in the following diagram:
Now, if you want to mail send off the patches to your favourite developer mailing list, you pop them all out:
$ guilt-pop all
Then, you hand-edit each patch so that each includes a little description file, then push them in again in order one by one. This is a bit crude, but Jeff is working on some magic to make this easier. When you've done pushing them in again, running
git-log should show you the changelog that you've done.
Finally, to mail them off, run:
$ guilt-patchbomb HEAD
A script will guide you through the process of patchbombing your mailing list.
Each patch stack is specific to whatever branch of your source tree you're working on. If you create a new branch, your Guilt files will be specific to that branch.
Good luck trying out Guilt. It's being actively developed at the moment, so expect it to become better over time :)